< backPoker, LLMs, and Image Processing
February 11, 2026A few days ago, I watched a YouTube that attempted to use AI agents to play poker against humans. The LLM obviously failed - throughout the video, it would claim to have a rank that was impossible to hold - a flush while on a backdoor was possible, or the LLM would output a fundemental misunderstanding of poker concepts such as blockers. Attempting to use an LLM to play Poker against a human will technically work, but it's the wrong tool for the job.
I'm attempting to build a game theory optimal poker solver to learn and understand how these solvers "play" poker, and the algorithms behind their seemingly magical output. One of the "nice things to have" while building the solver is the ability to read solver charts and parse them to a JSON output. The purpose of wielding this output-parsing ability is to compare popular solver output to my personal solver. A few weeks ago, I attemped to screenshot of [popular solver] output through Google Gemini, with the fold/call/raise percentage for the entire 13x13 solver grid returned as an array. I realized that I fell victim to the same mentality as using an LLM to play poker - I was attempting to use an LLM to solve a task a Python library could easily solve.
For those not familiar with Poker solvers, here's a sloppy image generated by Nano Banana of what a solver output typically looks like - it is a 13x13 grid with pocket aces on the top left, and pocket deuces on bottom right. The rate that you should perform a specific action highlighted in each cell.
The other day, I was introduced to a certain line of thinking regarding agent tooling, described in a blog post that I will link here if I can find it. In summary, the author stated that since LLMs can be specalized towards writing code, we should allow them to write their own tooling with customized output instead of off-the-shelf standard command line utilities such as grep or ls. Having an LLM write its own utlity for a specific purpose rather than bruteforcing solutions through pre-existing tools could be a productivity and efficiency booster.
I was recommended pi-mono for stateful tool calling. My understanding is that I could create my own Python utilities and call them from an agent.
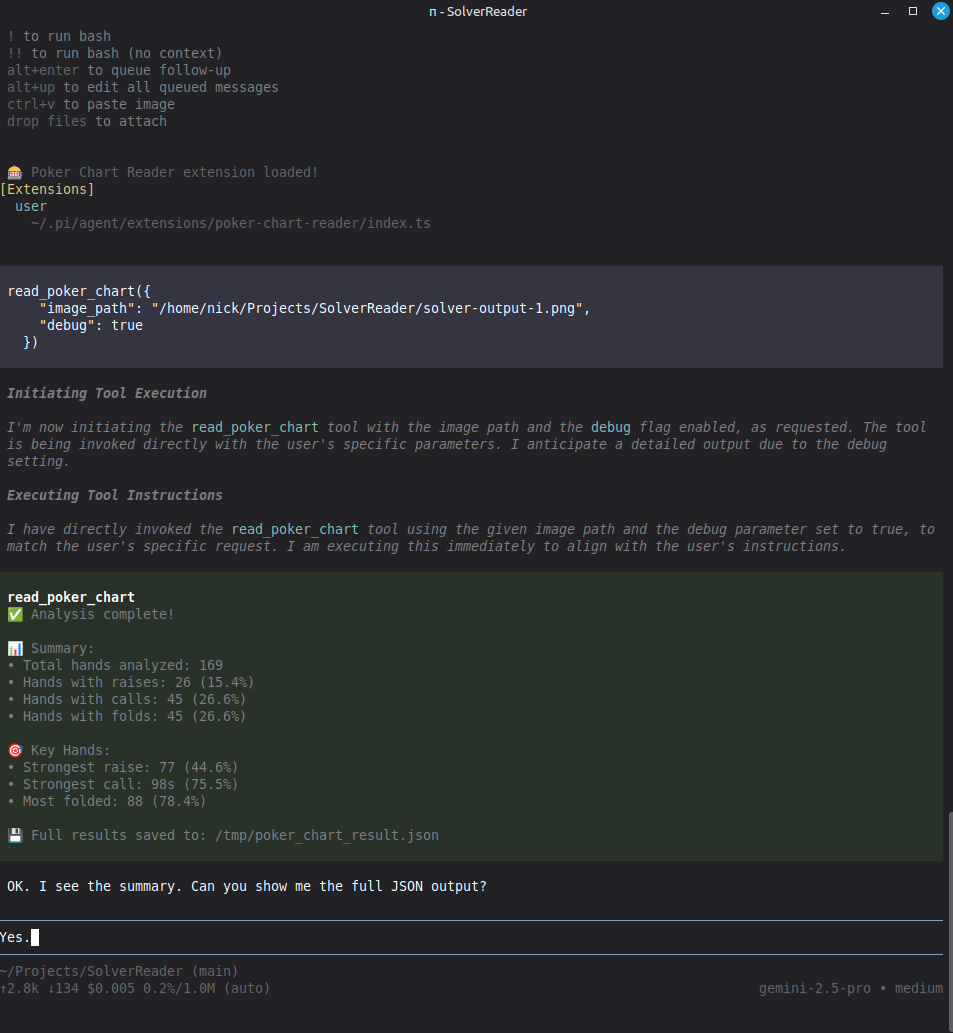
I used a combination of OpenCode and Kimi-K2.5 to implement an agent-tool workflow which accomplishes the following:
- OpenCV/PIL loads the solver output image and processes it.
- Analysis is performed on each cell in the image to extract fold/(check/call)/raise percentages.
- The processed solver output is dumped to a json file placed in /tmp/.
- A pi-extension is utilized to parse and summarize the json output of the OpenCV Python utility.
The extension created through pi-mono can be called either through OpenCode, or through my own application that would allow me to sift through solver output.
In summary, creating a custom CLI tool for the LLM to call led to a productivity boost in my development. I'm going to structure my projects around these mini-utilities when I find they will be necessary. If I need to accomplish image parsing in the future, I will use an LLM to write small Python utilities for it, rather than allowing a vision model to brute force a solution. Below is an example of the pi-layer running on top of the custom-made Python image processing tool.